Look how far precision medicine has come
Skeptics say drugs based on genetic insights have underdelivered. But look carefully and they’re everywhere.
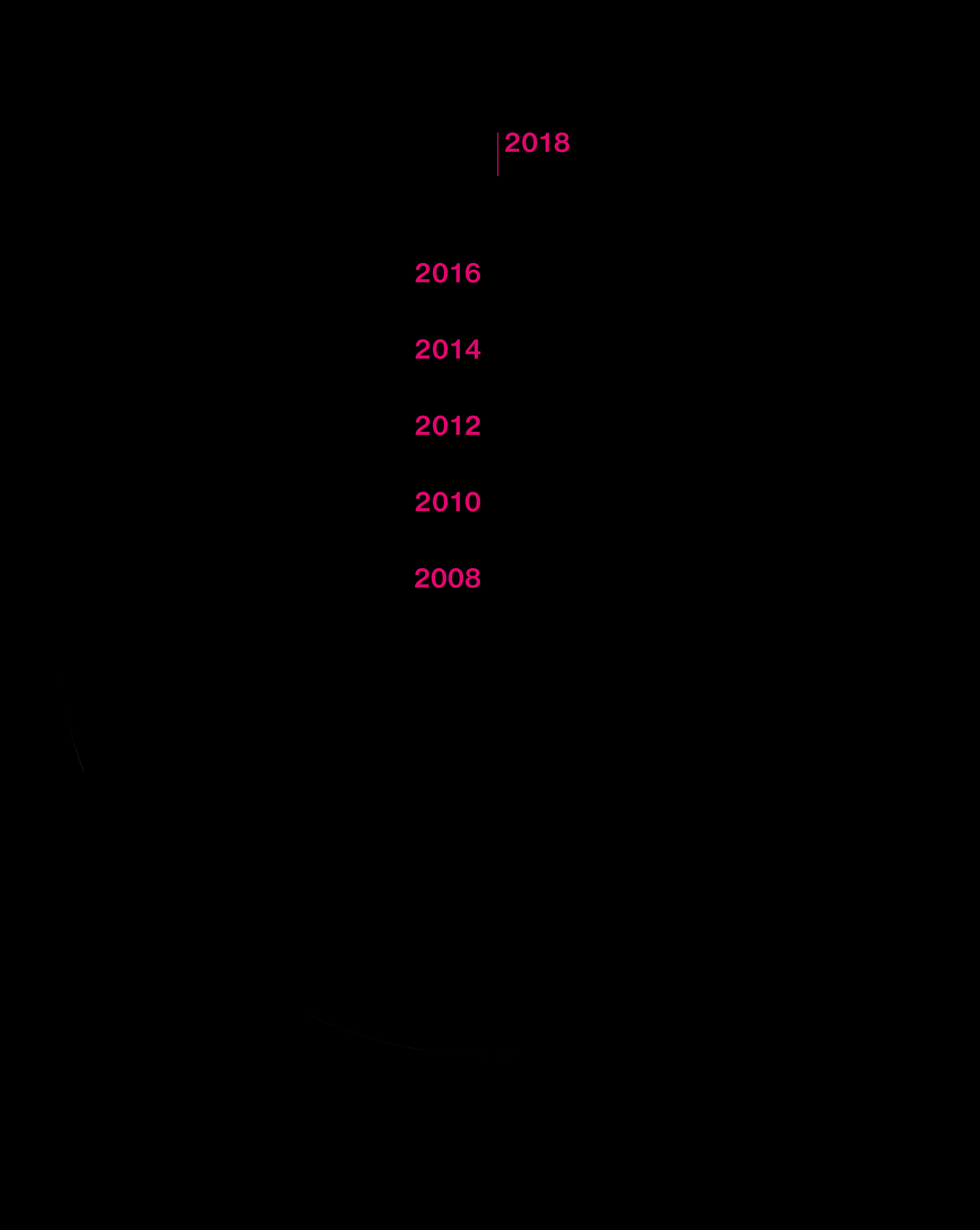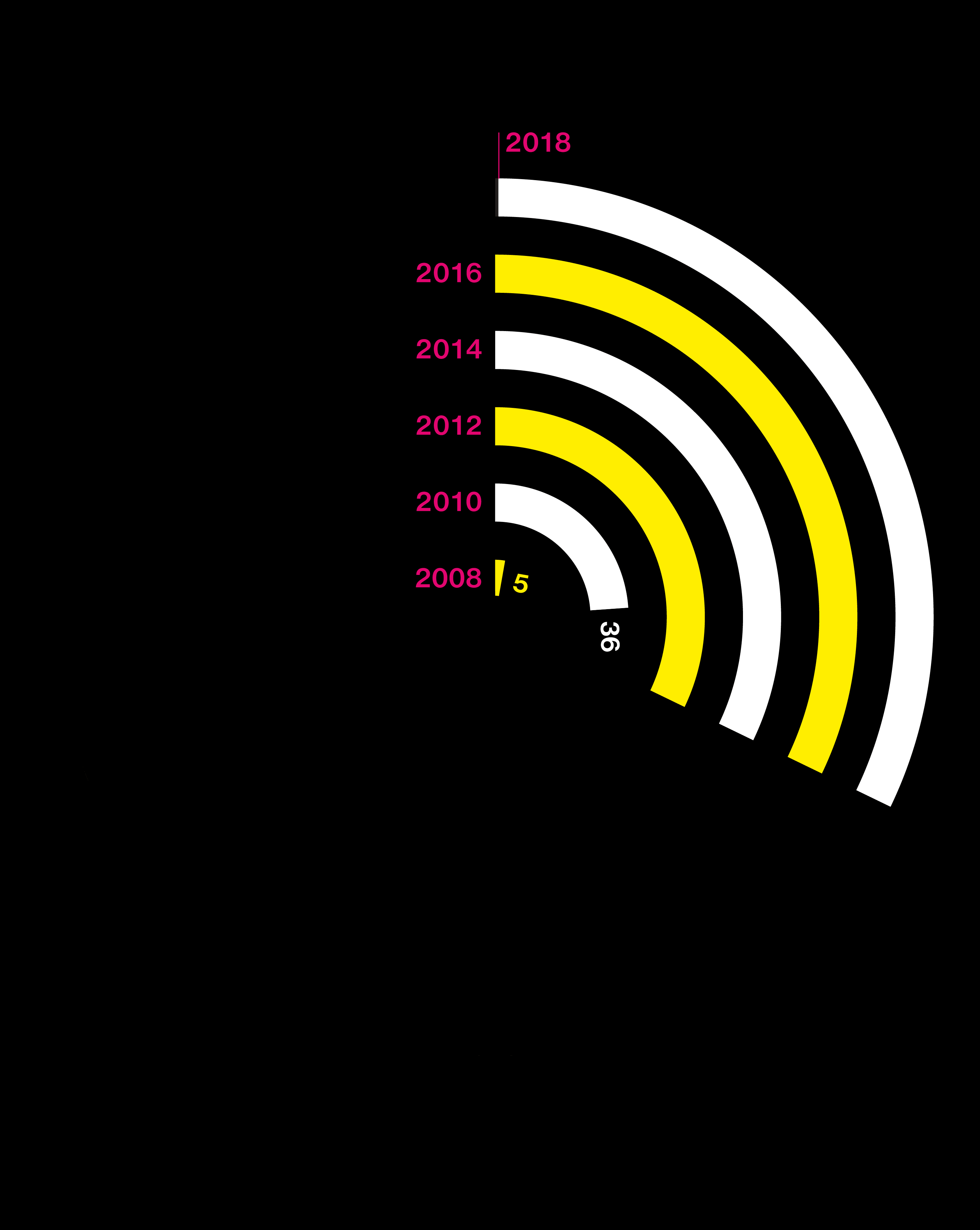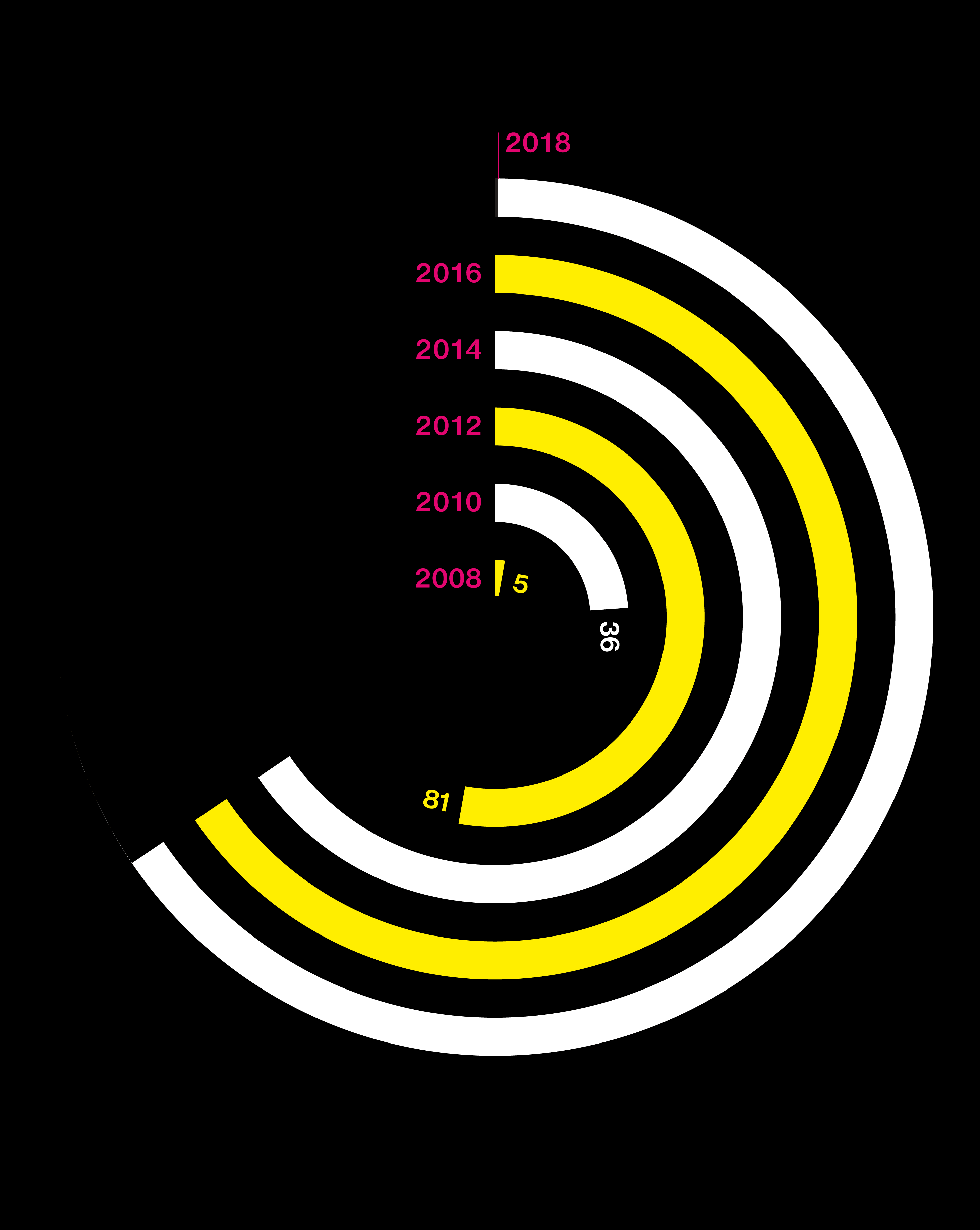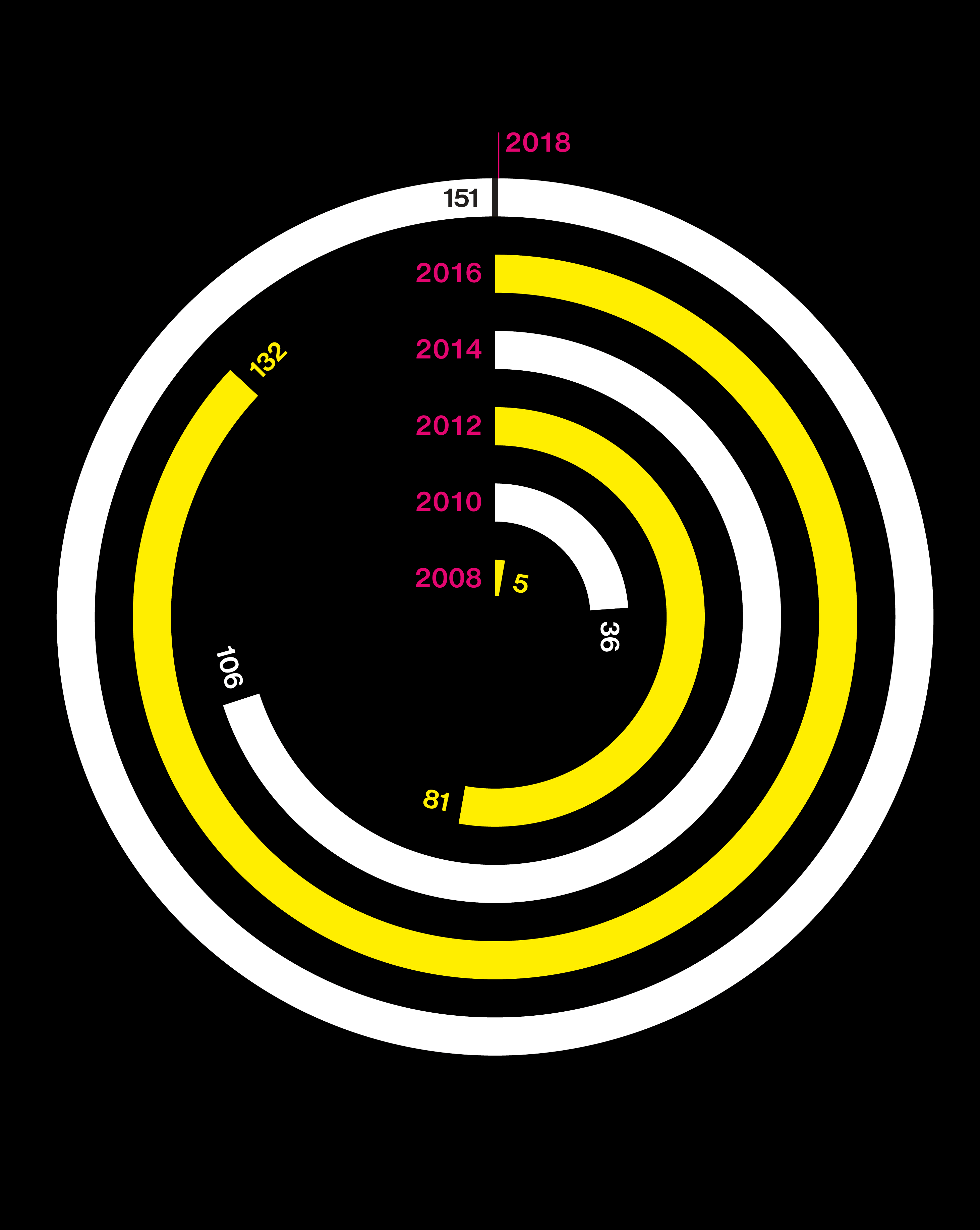
Sometime this fall, the number of people who have spit in a tube and sent their DNA to the largest consumer DNA testing companies, like Ancestry and 23andMe, is likely to top 20 million. The list by now is certain to include some of your classmates and neighbors. If you are just tuning in, this figure will seem huge. And you might wonder: how did we get here?
The answer is little by little. The number of people getting DNA reports has been doubling, roughly, every year since 2010. The figures are now growing by a million each month, and the DNA repositories are so big that they’re enabling surprising new applications. Consumers are receiving scientific predictions about whether they’ll go bald or get cancer. Investigators this year started using consumer DNA data to capture criminals. Vast gene hunts are under way into the causes of insomnia and intelligence. And 23andMe made a $300 million deal this summer with drug company GlaxoSmithKline to develop personalized drugs, starting with treatments for Parkinson’s disease. The notion is that targeted medicines could help the small subset of Parkinson’s patients with a particular gene error, which 23andMe can easily find in its database.
Ever since the Human Genome Project—the 13-year, $3 billion effort to decipher the human genetic code—researchers and doctors have been predicting the arrival of “precision medicine.” It’s a term with no agreed-upon definition, although it suggests most strongly just the kinds of medicines that Glaxo and 23andMe are pursuing: more targeted and more effective because they take into account a person’s particular genetic makeup. President Bill Clinton, at the unveiling of the genome’s first draft back in June 2000, said the data would “revolutionize the diagnosis, prevention, and treatment of most, if not all, human diseases.”
Seeking better drugs
The proportion of patients who actually benefit fron a best-selling drug in each category.
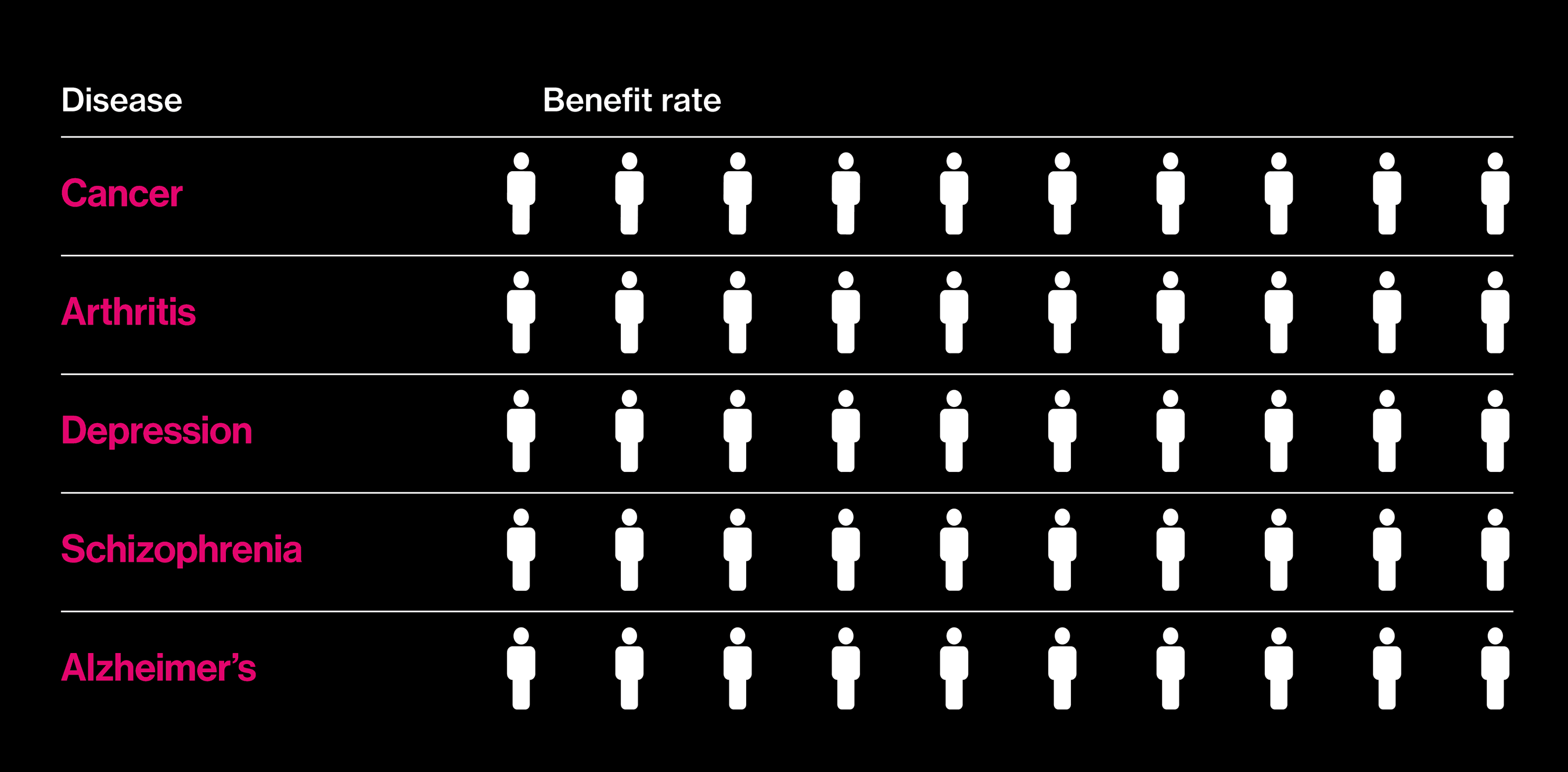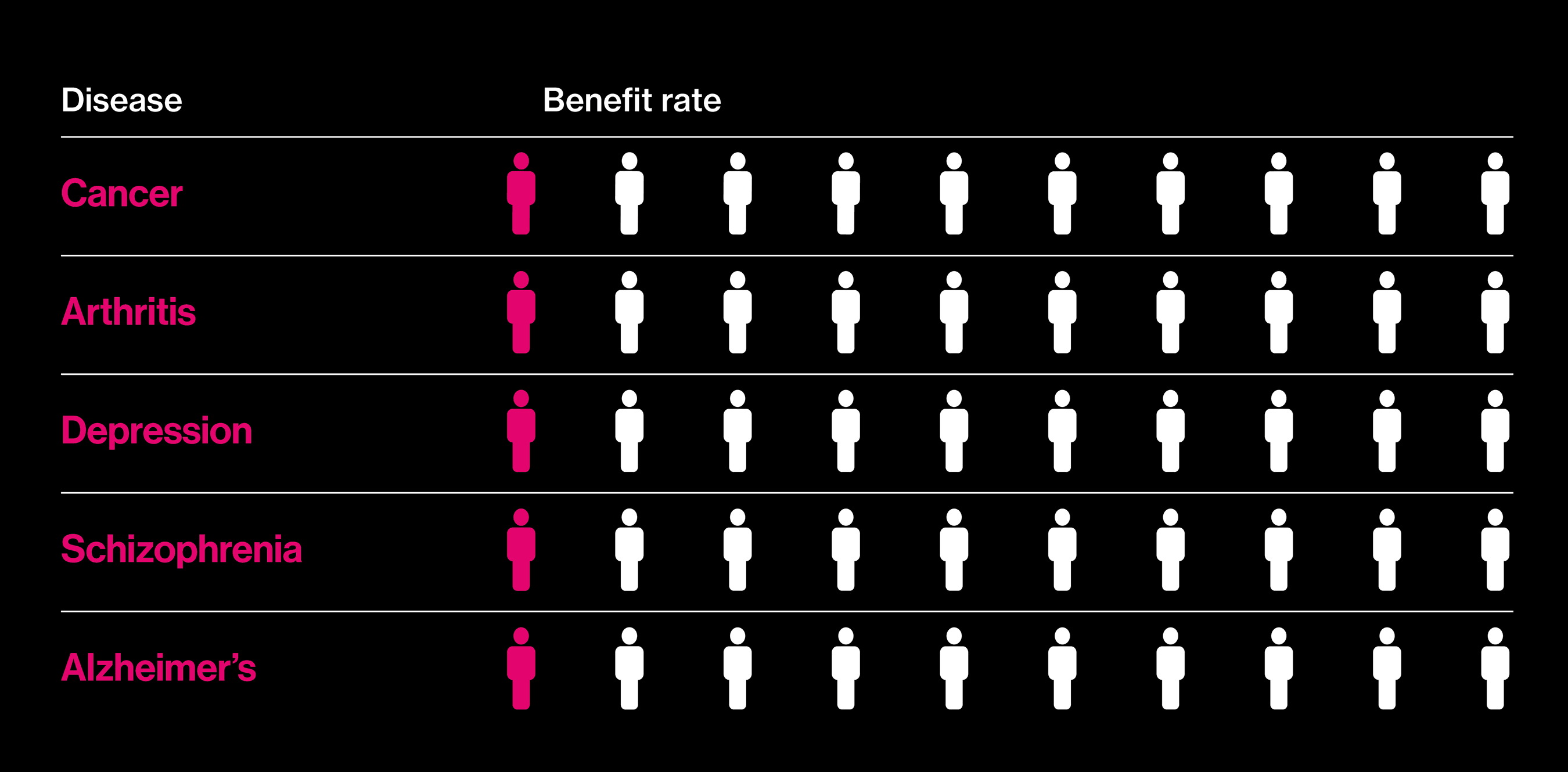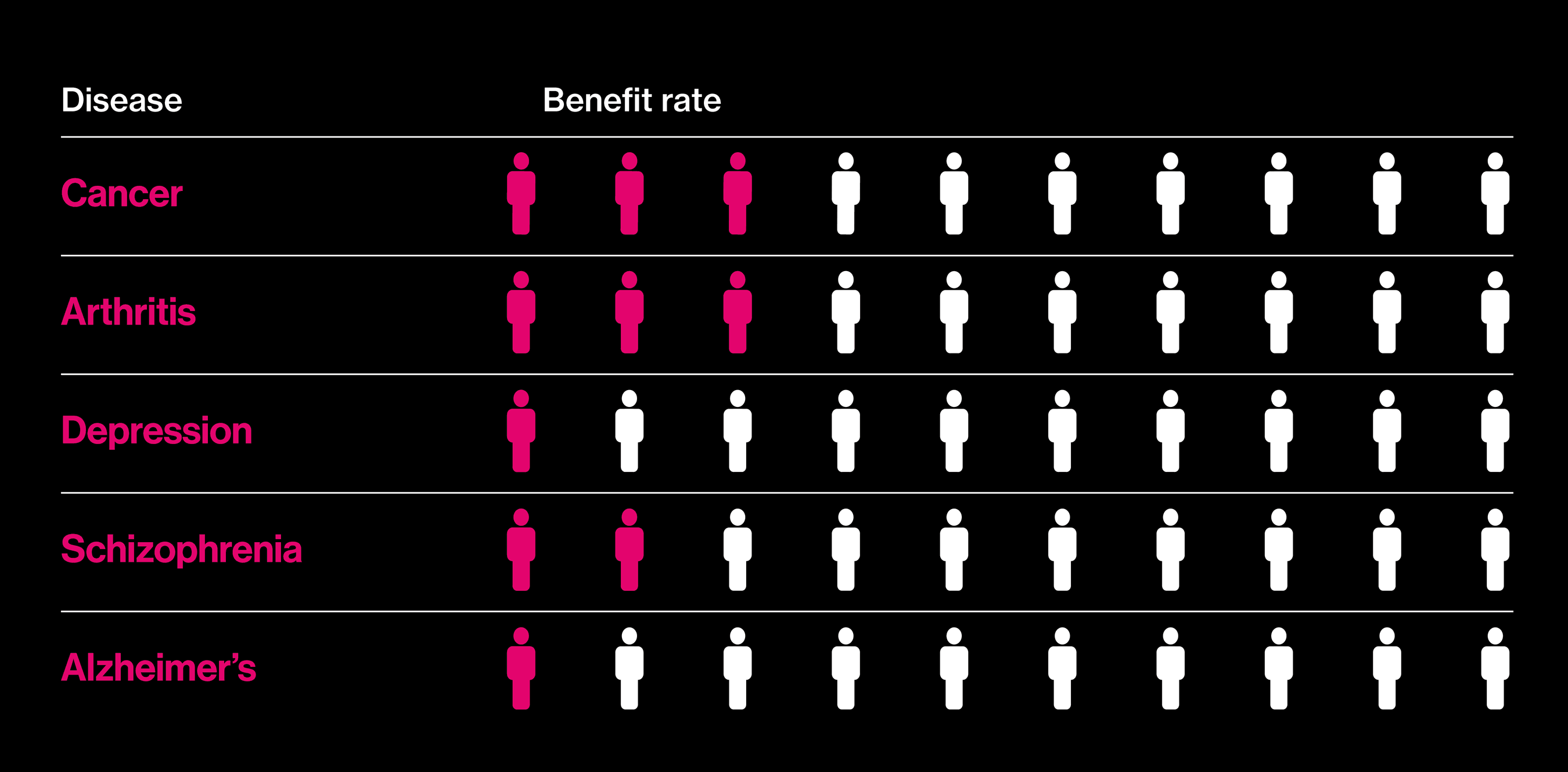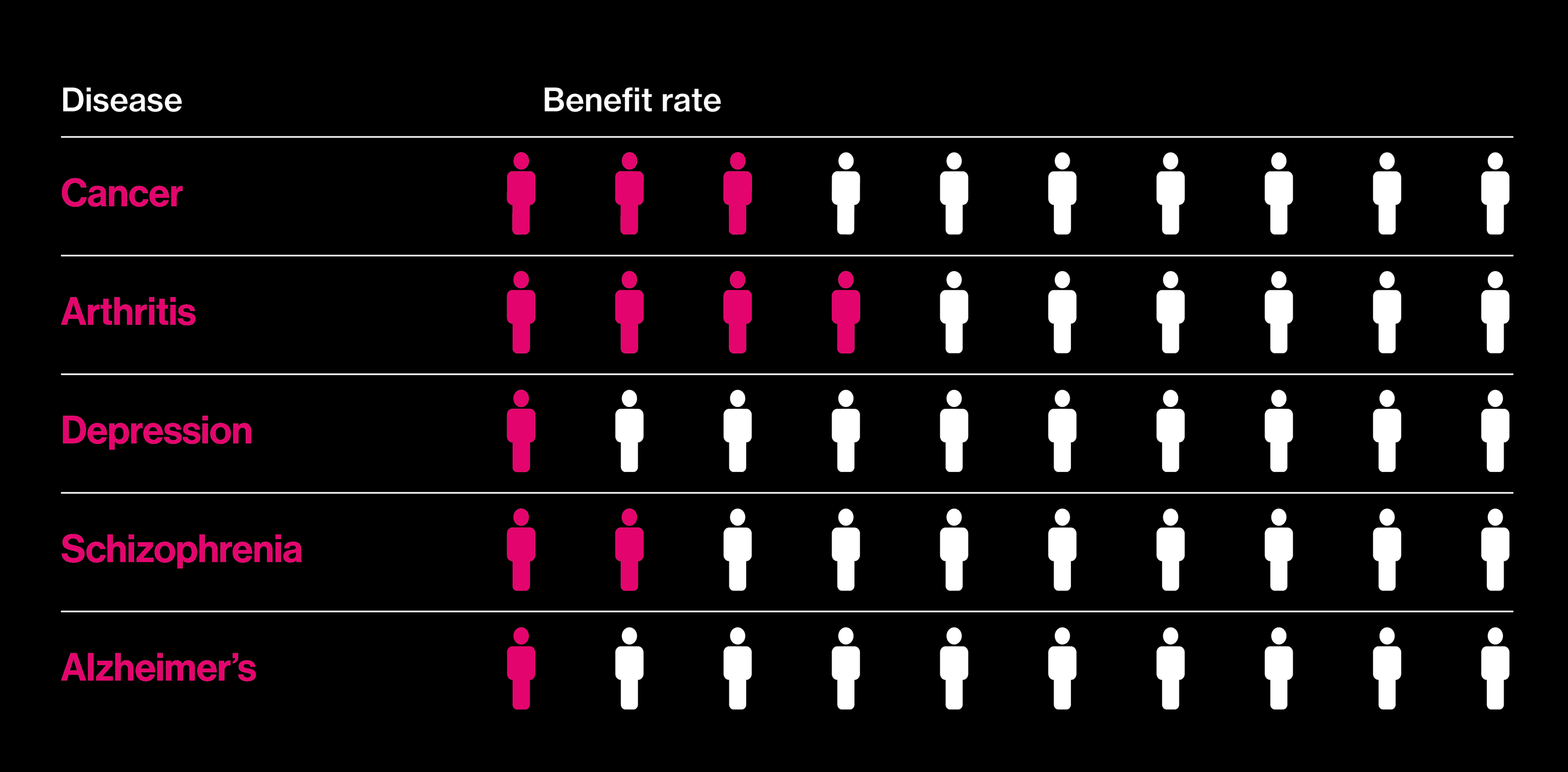
Almost two decades after those big promises, it is in vogue to question why precision medicine has not delivered more. A report in the New York Times this summer, noting that deaths from cancer still outnumber cures by a wide margin, asked: “Are We Being Misled About Precision Medicine?” One reason for this seemingly slow progress is that not all precision medicine involves drugs. As gene hunts gain in scope—the latest involve comparisons of more than a million people’s DNA and health records—an inconvenient fact about many common diseases has emerged: they don’t, by and large, have singular causes. Instead, many hundreds of genes play small roles, and there is no obvious point at which to intervene with a pill.
So instead of drugs, we are seeing a new predictive science in which genetic risk profiles may say which people should lower their blood pressure, which should steel themselves for Alzheimer’s, and which cancer patients aren’t going to benefit from chemotherapy and can skip the ordeal. To be sure, these sorts of prognostics aren’t widely accepted, and it’s hard to get people to change their behavior. Yet for many people, these predictions may begin to offer a concrete route to precision health and increased knowledge of their own biology.
Genetic information explodes
Left: Cost of sequencing a genome
Right: Number of people who have bought consumer DNA tests
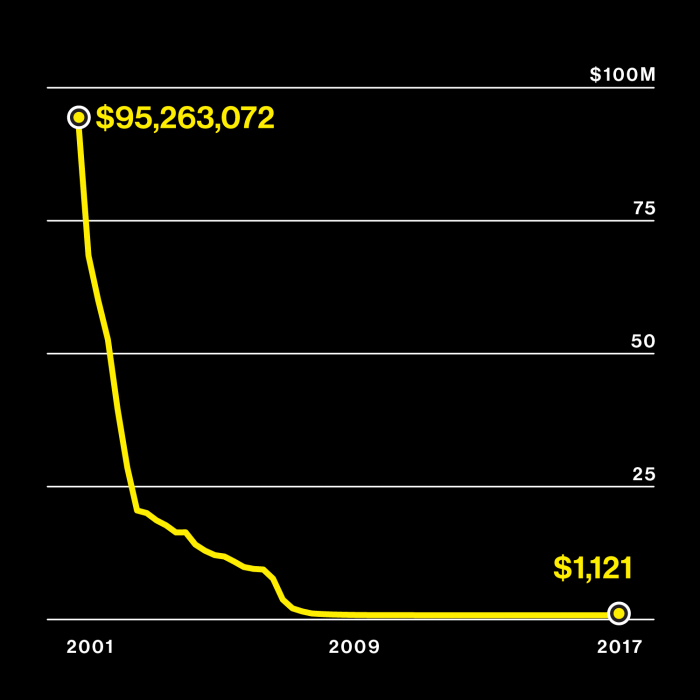
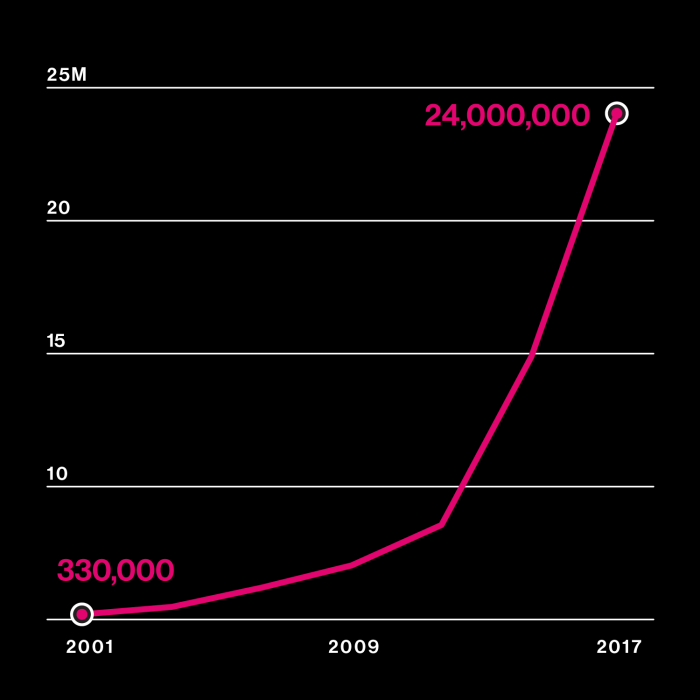
Look beyond cancer, and some definitive cures have arrived. As with those growing millions sending in their DNA, it’s easy to miss the change before it’s everywhere. Here are just two medications of note: a drug that mops up hepatitis C in 90% of those who take it and an experimental gene therapy that is curing a rare, fatal, and previously untreatable childhood disease, spinal muscular atrophy. Though these treatments come from different corners of biology, it’s what they have in common that’s important: each benefits from detailed understanding of genetic information and tools to control it.
To our thinking, these drugs display real precision. The hep C pill, called Sovaldi, consists of a chemical that is irresistible to the replicating virus, but when the drug comes in contact with the virus’s genome, replication quickly grinds to a halt. The treatment for spinal muscular atrophy, meanwhile, is a genetic replacement part. With gene therapy, doctors can add fresh DNA instructions to the child’s nerve cells. The dozen or so kids who’ve gotten the therapy at a young age don’t develop the disease.
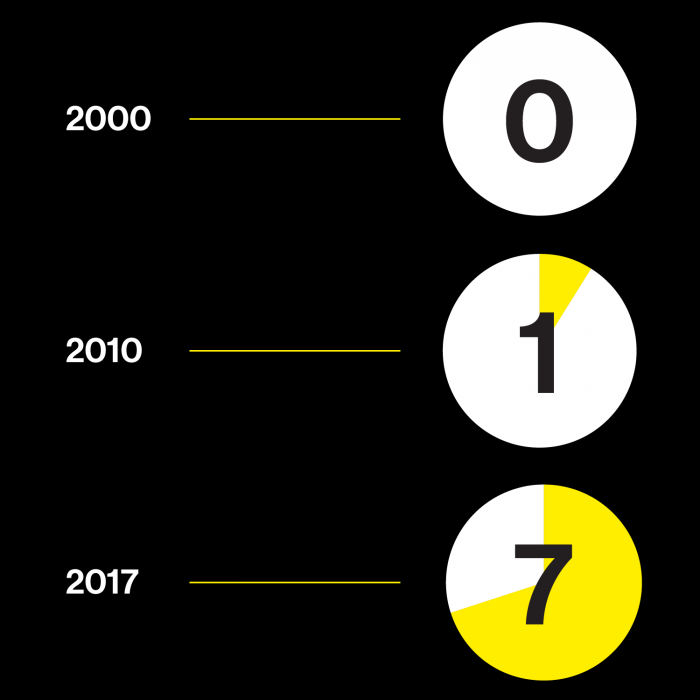
All this traces back to even before the Human Genome Project. Think instead of the foundational act of the biotechnology industry, 40 years ago. On September 6, 1978, Genentech announced “the successful laboratory production of human insulin.” Before then, diabetics had injected insulin from pigs. It took around two tons of pig parts to extract eight ounces (227 grams) of pure insulin. But Genentech had found a way to splice the human version of the insulin-producing gene into E. coli bacteria, which then manufactured the hormone. Genentech still keeps the 40-year-old press release online.
To the pharmaceutical houses of the 20th century, with their roots in commercial dye making and synthetic chemistry, these new biotech drugs looked at first like a sideshow. They were hard to make and inconvenient to take (by injection, mostly). The pharma giants could easily believe their way of doing things would always dominate. Until well into the 1990s, a single drug company, Merck, was more valuable than all biotech companies combined. It probably seemed as if biotech would never arrive—until it did. Of the 10 best-selling drugs in the US during 2017, seven (including the top seller, the arthritis drug Humira) are biotech drugs based on antibodies. Antibodies embody biological precision too. These tiny blood proteins, normally part of our immune response, fit—like a key in a lock—onto other molecules, like those dotting the surface of a cancer cell. And just like insulin, they’re often constructed using DNA code retrieved from our bodies.
Drugs based on DNA
Left: Percentage of drugs in development that may be tailored to a person's genetic profile
Right: Number of the 10 best-selling drugs in the US that are biological molecules
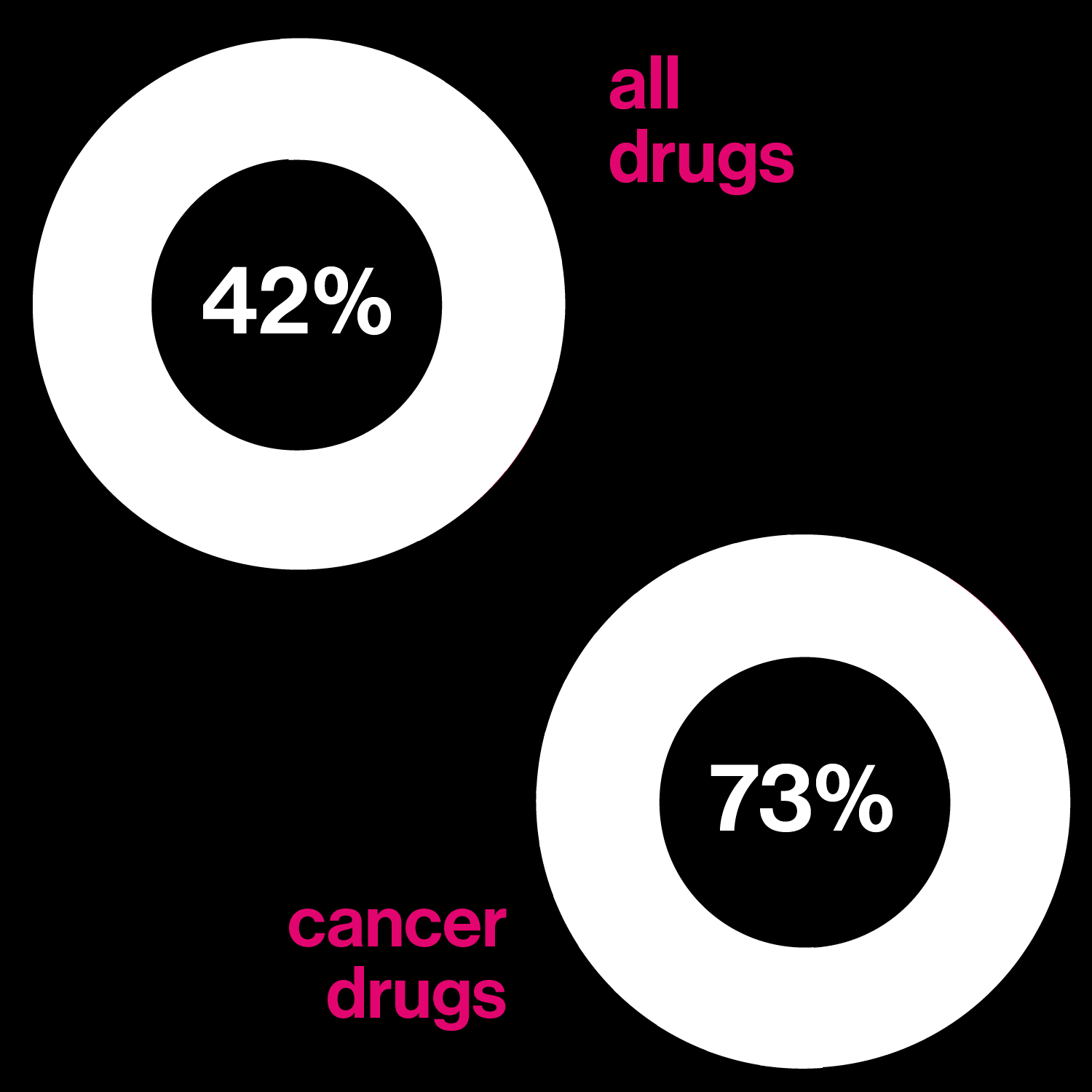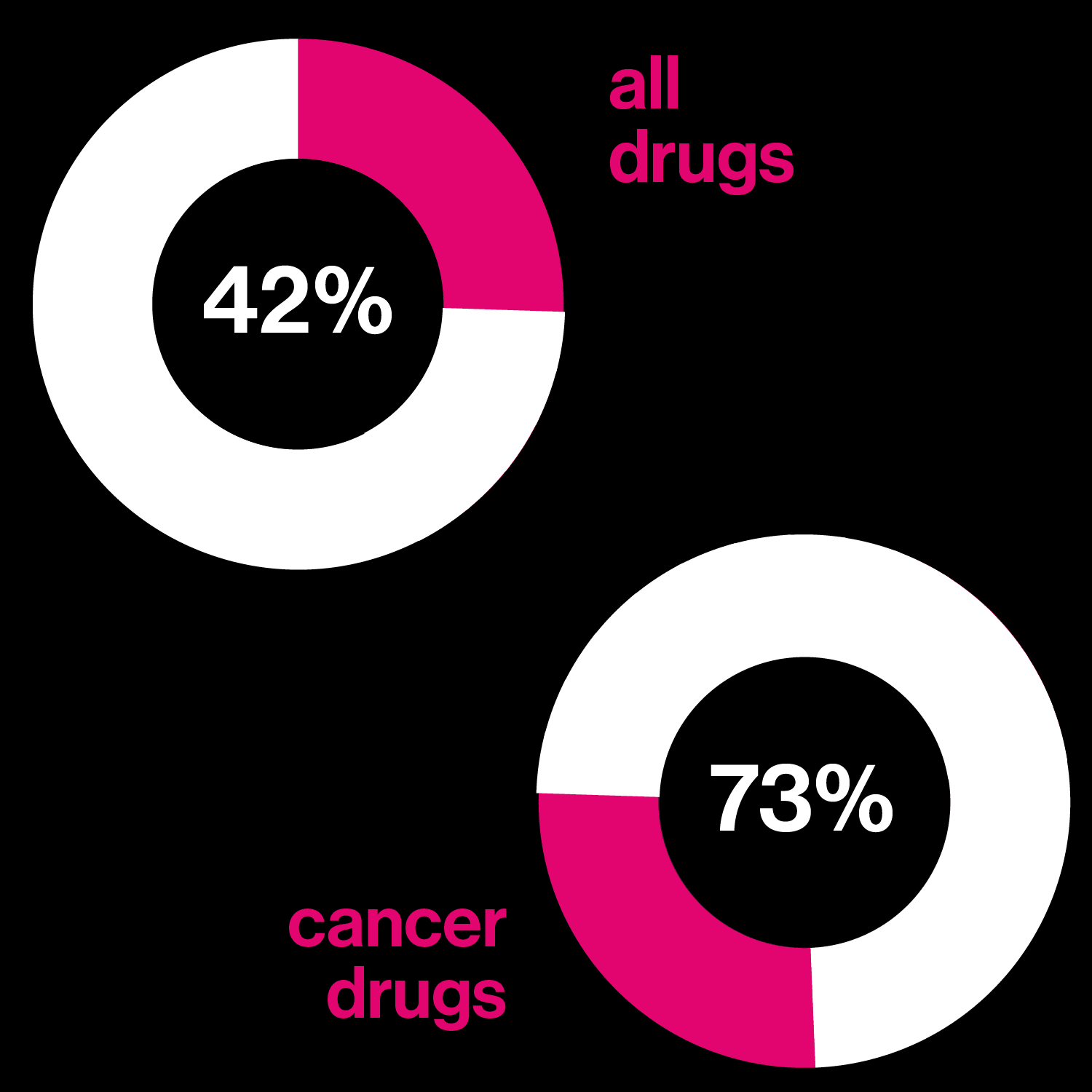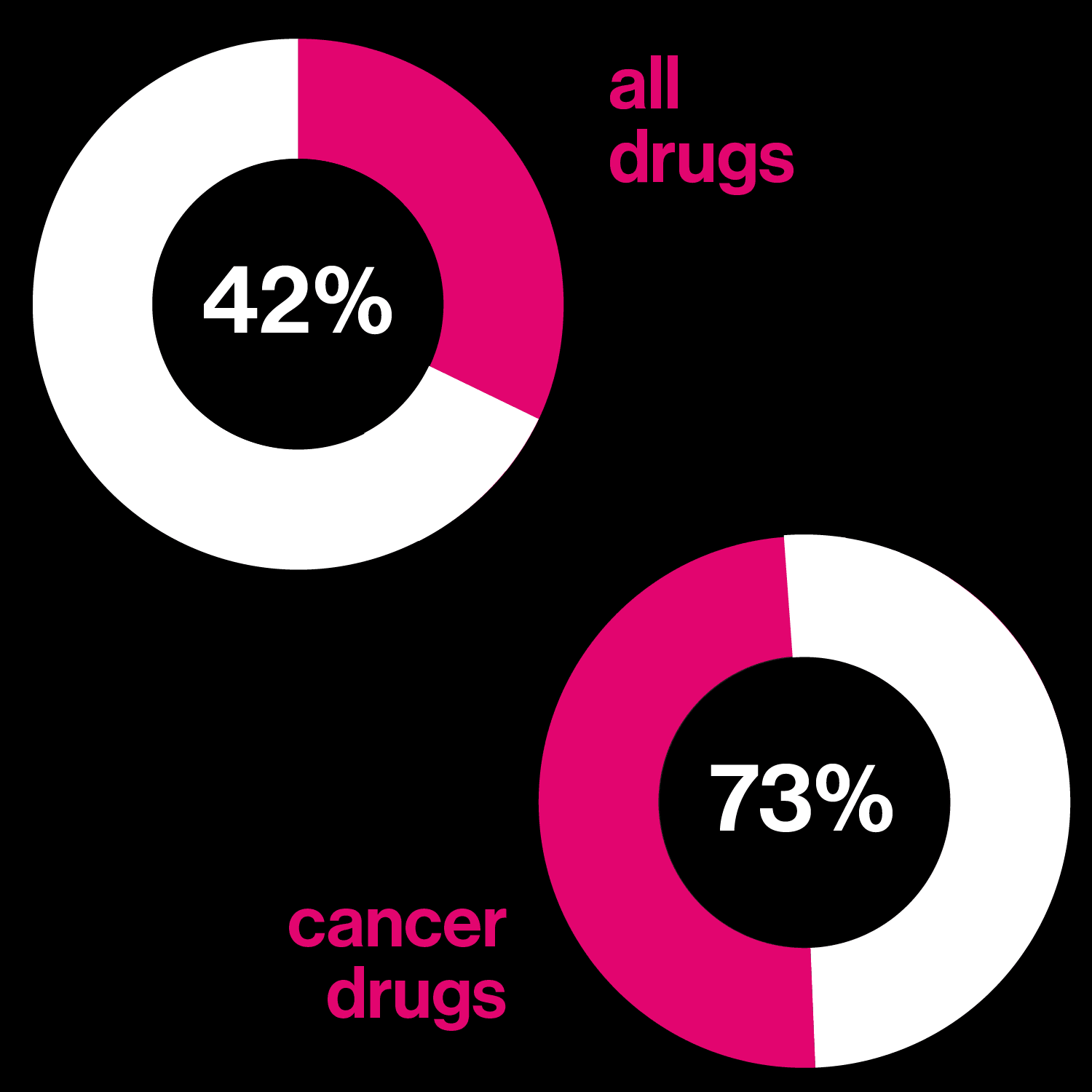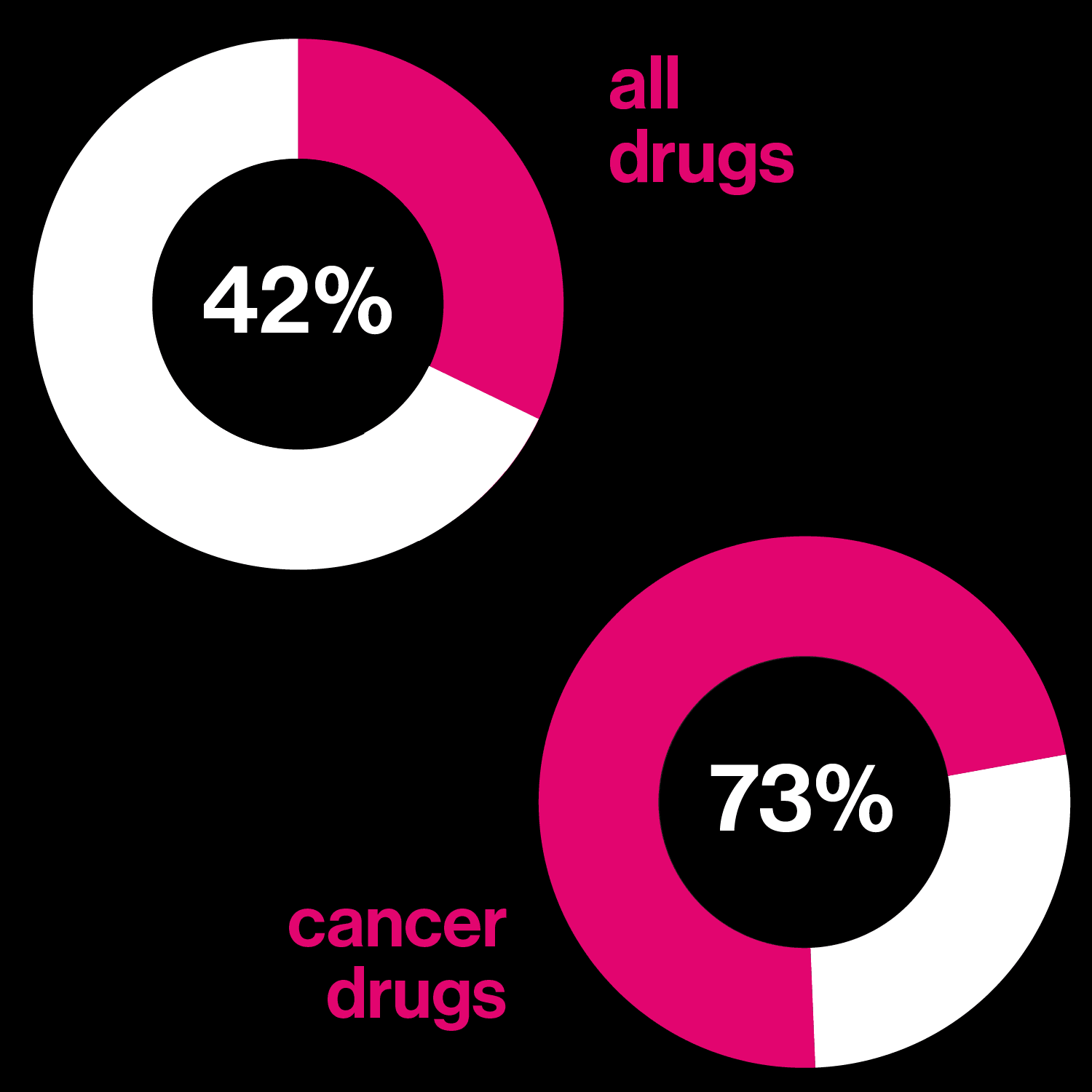
Insulin and antibodies are meant to work the same way on everyone. But no two people’s genomes are exactly the same—about 1% of the DNA letters differ between any two of us. Those differences can explain why one person is ill and another isn’t, or why one person’s version of diabetes is different from another’s. Drugs that take into account these differences in genetic information are called “targeted” drugs.
The cancer drug Herceptin, an antibody that reached the market in 1998, was among the first. It was effective, but mostly in people whose newly diagnosed breast cancer was growing because of specific genetic damage—about 20% of cases. It depended on the genome of the tumor itself. Herceptin came to market with the admonition that, to get it, you should first have a test to see if you would benefit. According to the US National Cancer Institute, there are now more than 80 such targeted medicines for cancer on the market.
Critics argue rightly enough that such medications still do too little for too few people at too great a cost (often $10,000 a month). In fact, on the whole, those who survive cancer still owe little to targeted drugs. “The single biggest determinant of who survives cancer is who has insurance,” Greg Simon, who leads the Biden Cancer Initiative, has said—not whether there’s a drug to match their mutation. Some think we are spending too much time searching under the lamplight shed by genetic tools. “Perhaps we had been seduced by the technology of gene sequencing—by the sheer wizardry of being able to look at a cancer’s genetic core,” a Pulitzer Prize-winning cancer doctor, Siddhartha Mukherjee, wrote this summer.
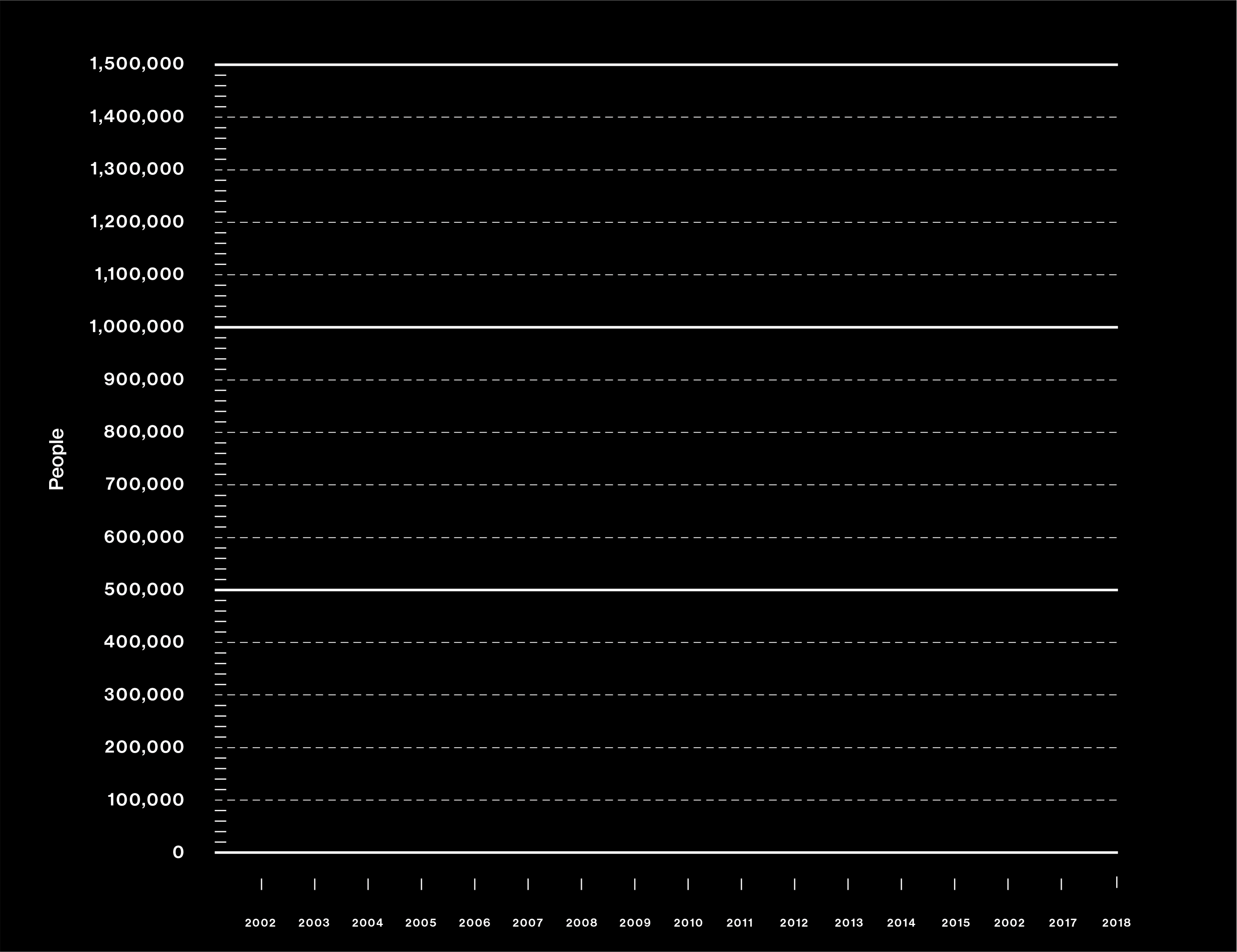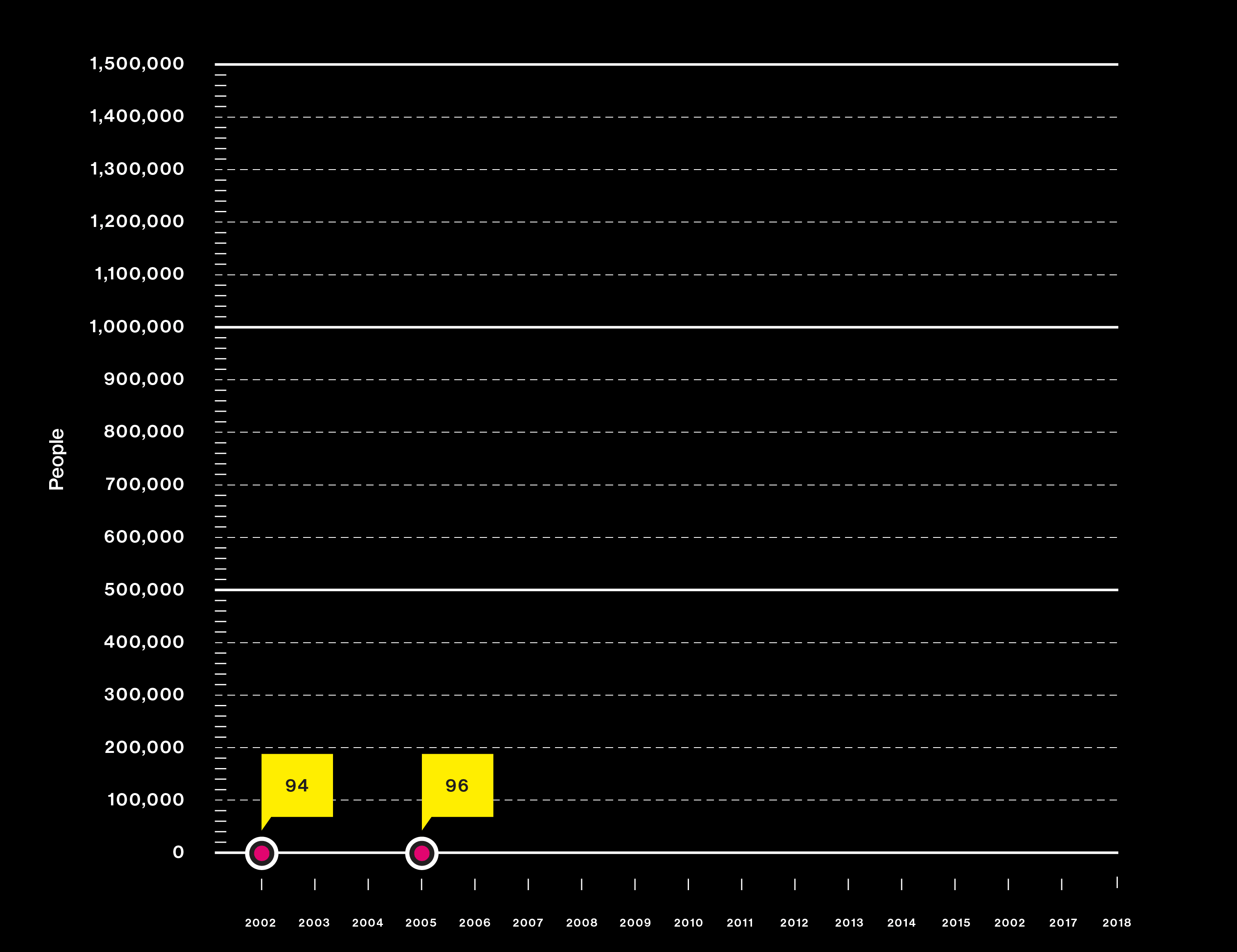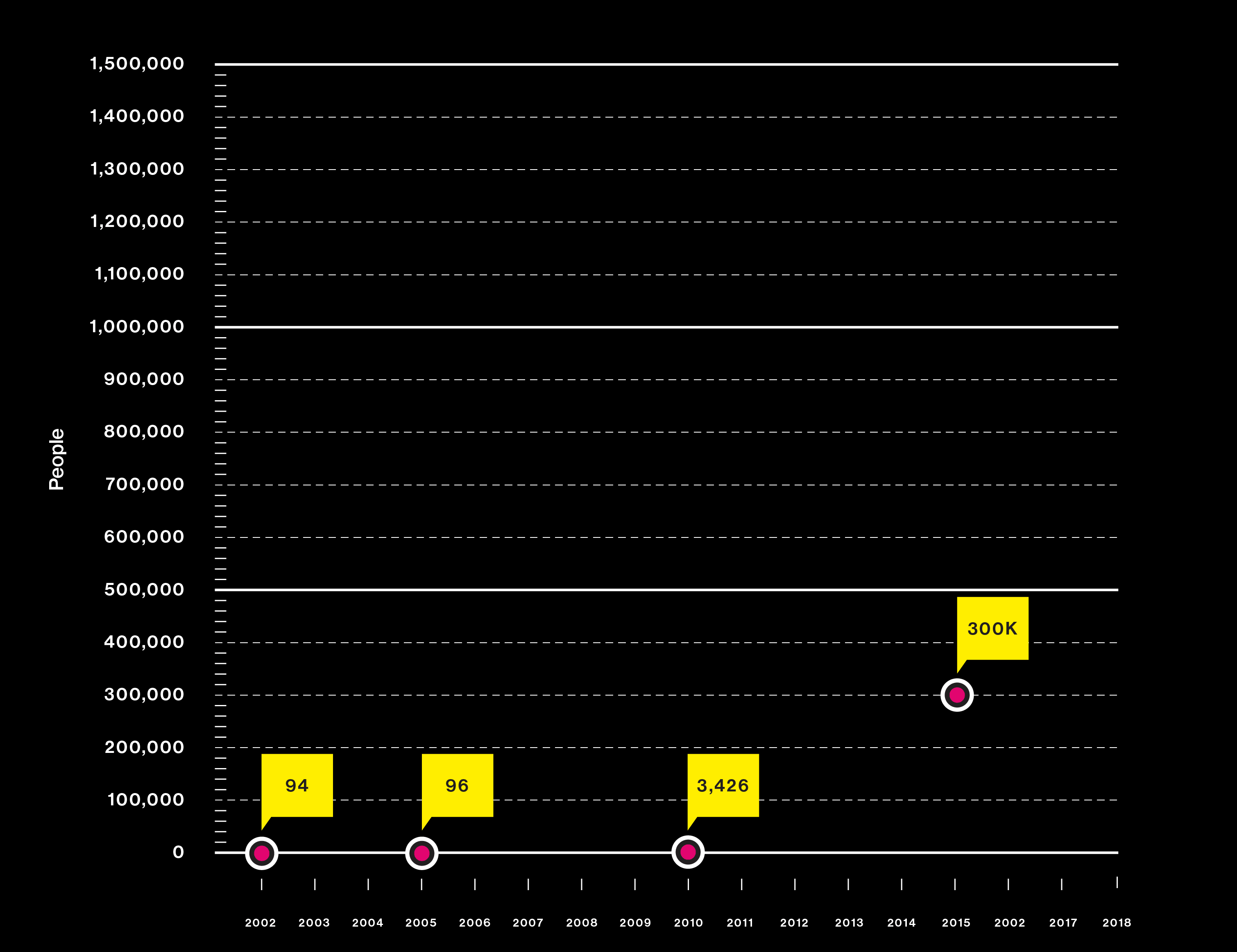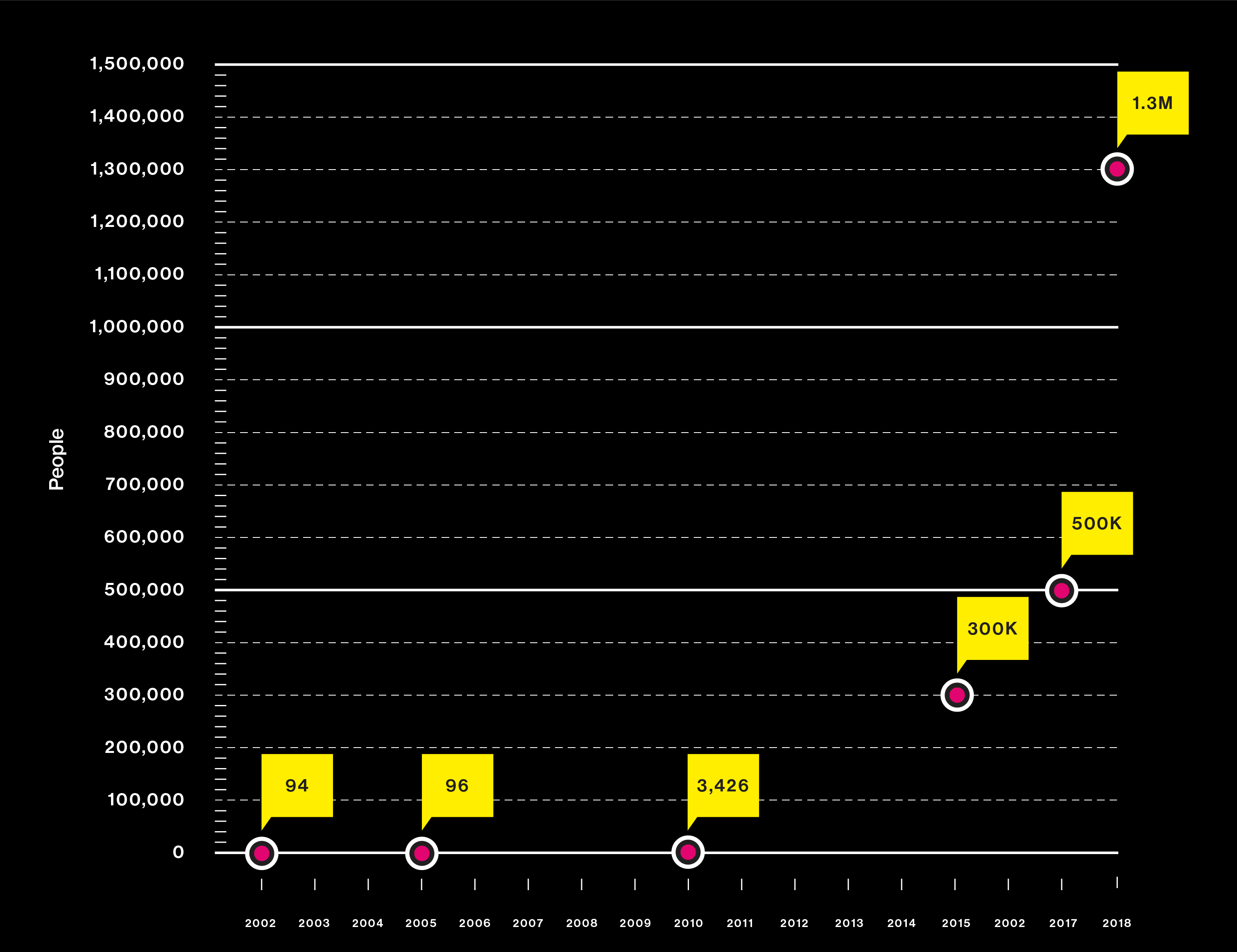
Big questions need big data
Studies are using DNA from more people than ever
Big questions need big data
2002
Japanese scientists use a new approach—the genome-wide association study—to hunt for the causes of heart attack.
2005
A gene hunt reveals critical mutations that increase the risk of macular degeneration, a common cause of blindness.
2010
Consumer test company 23andMe contributes user data to a search for Parkinson’s genes.
2013
The FDA cracks down on consumer test companies offering genetic health predictions from DNA, calling the results unreliable.
2015
Why are some people fatter than others? Clues from a genetic study are quickly offered to consumers in the form of “DNA diet” tests.
2017
A massive trove of gene data from the UK Biobank permits simultaneous analysis of 2,000 human traits and diseases.
2018
Researchers identify genes linked to educational success. They warn against using the results as a “DNA IQ test.”
A search for the genes behind insomnia is the largest genetic study ever. It relies heavily on the consumer DNA database of 23andMe.
He’s right that the impulse toward precision medicine, cost be damned, springs from new technology. It’s what it can do. And so you can be sure even more personalization is on the horizon. Genentech (which created Herceptin) now imagines what it calls “cancer vaccines,” tailored not just to broad subtypes of people but to the unique signature of a person’s tumor. The new approach involves collecting information about the peculiarities of a person’s cancer through high-speed genome sequencing; using software to analyze and predict what a custom biological drug would look like (they will be reverse images of antibodies, known as antigens, that stimulate the immune system); and then quickly manufacturing it. No two of these vaccines would be alike. Also, note this: if and when the US Food and Drug Administration approves these vaccines, it won’t be greenlighting a particular compound. Instead, it will approve a computerized process for turning DNA information into drugs.
Medicine as programmatic and predictable as a computer? The idea has begun to exert a potent appeal in Silicon Valley, where some of tech’s biggest names now see biology as “just a code” they can crack. Marc Andreessen (best known for inventing the web browser) is one of them. The venture fund he cofounded, Andreessen Horowitz or a16z, has set aside a total of $650 million since 2015 to put into biotech investments. As the firm’s blog states with awe, “You don’t just read the code of biology but you can also write, or design, with it.”
Welcome to biotech, a16z. Yet they’re on to something. Even 40 years after Genentech’s insulin press release, genetic engineering is a marvel worth rediscovering. The ability to see, understand, and manipulate human genes and the proteins they make is the great advance that is still unfolding in all its immense complexity four decades later. Biology isn’t anywhere as neat as a computer program, but little by little, we’re learning how to control it. To enzymes and antibodies we’ve added gene therapy and gene editing. We haven’t sequenced one genome—we’ve sequenced a million. An astute observer might realize we’ve already come a long way.
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.