This algorithm browses Wikipedia to auto-generate textbooks

Machine Learning—The Complete Guide is a weighty tome. At more than 6,000 pages, this book is a comprehensive introduction to machine learning, with up-to-date chapters on artificial neural networks, genetic algorithms, and machine vision.
But this is no ordinary publication. It is a Wikibook, a textbook that anyone can access or edit, made up from articles on Wikipedia, the vast online encyclopedia.
That is a strength. Crowdsourced information is constantly updated with all the latest advances and consistently edited to correct errors and ambiguities.
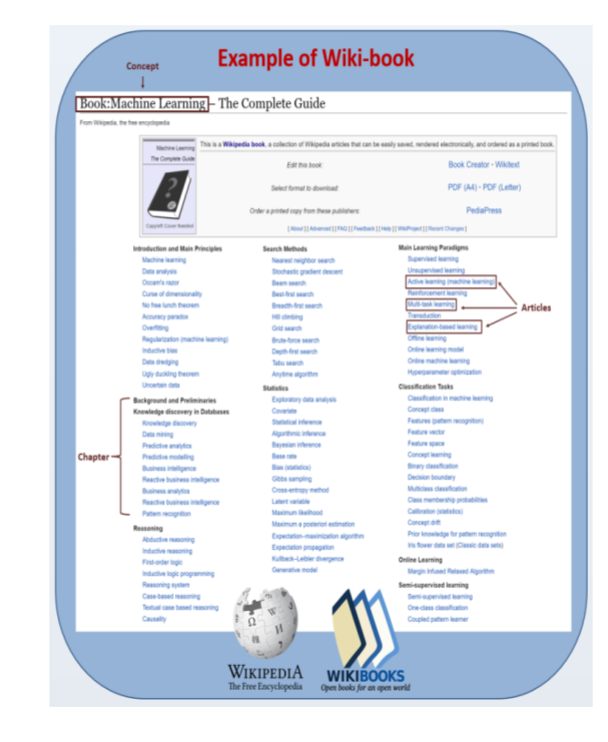
But it is also a weakness. Wikipedia is vast. Deciding what to include in such a textbook is a difficult task, which is perhaps why the book is so huge. With more than 550 chapters, it is not light reading.
That raises an interesting question. Given the advances in artificial intelligence in recent years, is there a way to automatically edit Wikipedia content so as to create a coherent whole that is useful as a textbook?
Enter Shahar Admati and colleagues at the Ben-Gurion University of the Negev in Israel. These guys have developed a way to automatically generate Wikibooks using machine learning. They call their machine the Wikibook-bot. “The novelty of our technique is that it is aimed at generating an entire Wikibook, without human involvement,” they say.
The approach is relatively straightforward. The researchers began by identifying a set of existing Wikibooks that can act as a training data set. They started with 6,700 Wikibooks included in a data set made available by Wikipedia for this kind of academic study.
Since these Wikibooks form a kind of gold standard both for training and testing, the team needed a way to ensure their quality. “We chose to concentrate on Wikibooks that were viewed at least 1000 times, based on the assumption that popular Wikibooks are of a reasonable quality,” they say.
That left 490 Wikibooks that they filtered further, based on factors such as having more than 10 chapters. That left 407 Wikibooks that the team used to train their machines.
The team then divided the task of creating a Wikibook into several parts, each of which requires a different machine-learning skill. The task begins with a title generated by a human, describing a concept of some kind, such as Machine Learning—The Complete Guide.
The first task is to sort through the entire set of Wikipedia articles to determine which are relevant enough to include. “This task is challenging due of the sheer volume of articles that exist in Wikipedia and the need to select the most relevant articles among millions of available articles,” say Admati and co.
To help with this task, the team used the network structure of Wikipedia—articles often point to other articles using hyperlinks. It is reasonable to assume that the linked article is likely to be relevant.
So they started with a small kernel of articles that mention the seed concept in the title. They then identified all the articles that are up to three hops away from these seeds on the network.
But how many of these linked articles should be included? To find out, they began with the titles of the 407 Wikibooks created by humans and performed the three-hop analysis. They then worked out how much of the content in the human-created books were included by the automated approach.
It turns out that the automated approach often included much of the original Wikibook content but significantly more besides. So the team needed some other way to prune the content further.
Again, network science comes into play. Each human-generated Wikibook has a network structure of its own, determined by the number of links pointing in from other articles, the number of links pointing out, the page rank listing of the included articles, and so on.
So the team created an algorithm that looked at each automatically selected article for a given topic and then determined whether including it in a Wikibook would make the network structure more similar to human-generated books or not. If not, the article is left out.
The next step is to organize the articles into chapters. This is essentially a clustering task; to look at the network formed by the entire set of articles and work out how to divide it into coherent clusters. Various clustering algorithms are available for this kind of task.
The final step is to determine the order in which the articles should appear in each chapter. To do this, the team organize the articles in pairs and use a network-based model to determine which should appear first. By repeating this for all combinations of article pairs, the algorithm works out a preferred order for the articles and thereby the chapters.
In this way, the team was able to produce automated versions of Wikibooks that had already been created by humans. Just how well these automated books compare with the human-generated ones is hard to judge. They certainly contain much of the same material, often in a similar order, which is a good start.
But Adamti and co have a plan for determining the utility of their approach. They plan to produce a range of Wikibooks on subjects not yet covered by human-generated books. They will then monitor the page views and edits to these books to see how popular they become and how heavily they are edited, compared with human-generated books. “This will be a real-world test for our approach,” they say.
That’s interesting work that has the potential to produce valuable textbooks on a wide range of topics, and even to create other texts such as conference proceedings. Just how valuable they will be to human readers is yet to be determined. But we will be watching to find out.
Ref: arxiv.org/abs/1812.10937 : Wikibook-Bot—Automatic Generation of a Wikipedia Book
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.